Realizacje
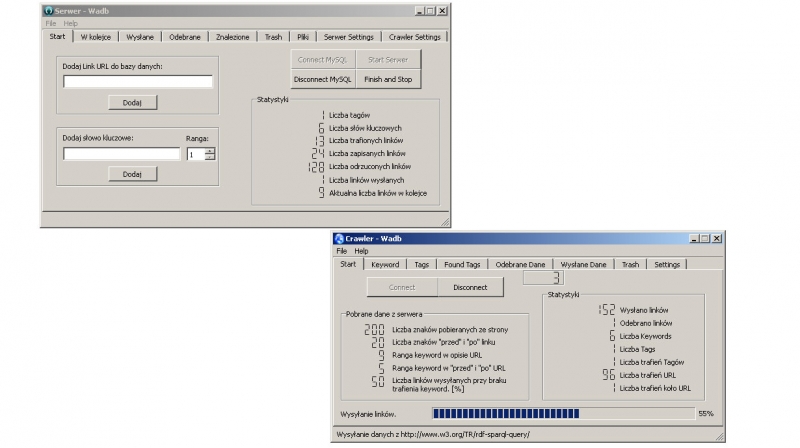
System robotów równoległych przeszukujących strony WWW
Opis:
Celem pracy było stworzenie „systemu robotów” przeszukujących strony internetowe. System składa się z serwera oraz wielu robotów, który mogą być uruchomione na dowolnym komputerze. Serwer kontroluje pracę całego systemu. Kontrola ta polega między innymi na wysyłaniu parametrów i adresów stron WWW do analizy. Każdy robot po ukończeniu analizy przesyła serwerowi zgromadzone dane i oczekuje na kolejne zadania. Aplikacje zostały napisane w oparciu o biblioteki QT.
Serwer jest odpowiedzialny za gromadzenie następujących danych:
-
adresy URL – możemy podzielić na:
- adresy URL które zostały już przeanalizowane przez roboty.
- adresy URL oczekujące na analizę.
- adresy URL w których znaleziono słowa kluczowe.
-
słowa kluczowe – decydują o tym jaka tematyka nas interesuje. Dla każdego słowa kluczowego ustalamy rangę (priorytet). Na podstawie słów kluczowych i rangi każdego słowa wyliczana jest ranga znalezionego adresu URL. Parametr ten decyduje o kolejności w jakiej linki wysyłane są do analizy.
-
pliki – serwer pobiera pliki o rozszerzeniach zdefiniowanych w zakładce Pliki. W zakładce tej definiujemy również rozszerzenia plików, które zostaną odrzucone. Pliki są pobierane w losowym przedziale czasowym i zapisywane jako id.zdefiniowane_rozszerzenie w folderze files. Numer id to unikalny numer rekordu z tabeli przechowującej adresy URL plików.
-
tagi i zawartość strony – informacje te zapisywane są w pliku tekstowym o nazwie id.txt, który zostaje umieszczony w folderze found. Numer id to unikalny numer rekordu z tabeli przechowującej adresy URL. Zawartość strony jest przesyłana jeśli analizowany link zawierał zdefiniowane słowa kluczowe. Tagi są zapisywane niezależnie od występowania słów kluczowych. W przypadku występowania wielu tagów na stronie są one zapisywane jeden pod drugim.
-
parametry – odpowiedzialne za sterowanie robotami. Decydują o liczbie znaków pobranych ze strony, gdy link zawierał słowa kluczowe, liczbie znaków pobranych przed i po adresie URL, randze słowa kluczowego w linku i w znakach przed i po adresie URL oraz o tym ile linków zostanie pobranych jeśli żadne słowo kluczowe nie występuje na stronie (parametr podawany w %). Ostatnia zmienna jest brana pod uwagę od poziomu drugiego Dzięki tej opcji ograniczamy przeszukiwanie stron, na których nie występują interesujące nas informacje. Ograniczenie nie działa w przypadku braku zdefiniowania słów kluczowych.
Głównym zadaniem robota jest analizowanie stron. Analiza ta polega na pobieraniu adresów URL do kolejnych stron internetowych, wyszukiwanie słów kluczowych w linku URL i opisie, a także pobieranie zdefiniowanych tagów. Robot sterowany jest przez serwer, z którego przesyłane są adresy URL, słowa kluczowe, tagi oraz dodatkowe parametry określające pracę robota.
Po włączeniu robot próbuje nawiązać połączenie z serwerem. W przypadku błędu czeka około 30 sek. i ponawia próbę. Po udanym połączeniu robot pobiera listę adresów URL do analizy, a także parametry potrzebne do dalszej pracy. Jeśli robot nie posiada aktualnej listy słów kluczowych ani tagów są one pobierane z serwera. Następnie robot kończy połączenie z serwerem i przystępuje do pobrania pierwszej strony z otrzymanej listy. W przypadku błędu pobierania (strona nie istnieje) robot komunikuje serwerowi zakończenie analizy danego adresu URL, a następnie połączenie jest kończone. Robot pobiera kolejną stronę z nadesłanej listy do analizy. W przypadku braku stron do analizy robot łączy się z serwerem robotów i pobiera kolejną listę. Po pobraniu strony robot przystępuje do jej analizy. Wyszukuje linki i poddaje je analizie pod kątem obecności słów kluczowych. Kolejny krok to znalezienie tagów oraz pobranie ciągu znaków ze strony jeśli analizowana strona była odpowiednio oznaczona. Po pobraniu wszystkich danych, robot ponawia połączenie z serwerem i wysyła kolejno wszystkie linki, a następnie tagi i ciąg znaków, po czym zgłasza koniec analizy strony. Robot pobiera kolejny adres URL z listy do analizy lub komunikuje się z serwerem w celu pobrania nowej listy adresów URL.